前言
最近有参与蔚蓝档案二创相关的制作,偶尔会有需要把游戏内的素材解包作为参考的情况。
4月25日的游戏更新使得媒体文件的保存方式发生了一些改变,导致对应的解包脚本需要进行修改。
本文的主要目的是分析文件储存方式的更变,并尝试提供一种应对方法。
文件存储方式
游戏的媒体素材都存储在名为 MediaPatch 的文件夹中。
文件夹中包含的内容如下:
MediaPatch
- 4700869051889956923_2401210236
- ...
- MediaCatalog.hash
形如 一串数字 + 下划线 + CRC 的文件即为我们所需的媒体文件。这样的文件经过游戏的处理,隐去了原有的文件名,而我们所需要做的就是还原出真实的文件名以及格式。
但光看这样的文件名,根本无从下手,只能根据大小(或文件头)来猜测文件类型,更何谈还原出原有的文件名呢?
前面我们提到,媒体文件的保存方式发生过一些改变。以往的版本中,在这个文件夹下,还存有一个名为 MediaCatalog.json 的文件。这个文件里储存了所有真实的文件名,以及一些额外的信息,供游戏读取并调用。
{
"Table": {
"video/xxx": {
"MediaType": 2,
"path": "Video/xxx.mp4",
"FileName": "xxx.mp4",
"Bytes": 3489522,
"Crc": 2401210236
},
...
}
}得知了文件的 CRC 后,我们就可以在目录下寻找文件名以这个 CRC 结尾的文件,并将该文件重命名为 path 字段的文件名,就还原出了真实的文件名。
但是由于版本更新,这个文件已经不存在了(如果之前安装过,文件还会有,但是是上个版本残留的)。我们可以通过一些特殊方式,获取到下载资源文件的网址,并尝试访问 MediaCatalog.json,结果会返回该文件不存在。这意味着新版已经放弃了以该文件存储相关信息,转而使用其他文件来存储了。没有这个文件,我们无法开展文件名的解密。可是这个新的文件,又要从何找起呢?
几天前我也是这样一头雾水,把整个游戏文件翻了个底朝天,也没有找到同样存储媒体文件信息的新文件。
正当我一筹莫展之际,无意中翻到了 GitHub 上的一个 issue。其中提到:
調べてみると、どうやらMediaCatalog.jsonがバイナリに変換されてMediaCatalog.bytesに保存されているようです。
I think the game automatically created the bytes file and kill it after the game reading completed.
If I close the game before the game stop loading, the bytes file will remain.
这无疑解答了困惑我许久的问题:新的文件去哪里了?为什么我们没有找到新的存储文件?
根据回答,新的版本转而以 MediaCatalog.bytes 来存储媒体相关信息。并且仅在游戏加载资源文件时,才会生成这个文件,而在加载完成后,则会删除掉这个文件。如果我们在游戏加载时强制退出游戏,这个文件会保存下来。
有了这个文件,我们就可以重新开展媒体文件解包的工作了。不过在这之前,我们先尝试解决如何快速获得这个文件的问题。
在游戏加载时退出以获得文件,不失为一种可行的方法。但对于一些直接从游戏资源服务器上获取资源文件的工程,这种方法仍然需要安装游戏,并运行游戏安装资源文件,才能进行此文件的提取。这无疑极大阻碍了相关工程的进展。有没有一种方法能够像之前一样,在避免安装游戏文件的同时,能够获取到 MediaCatalog.bytes,并且能方便地集成到原有的工程中呢?
答案是,有,并且很简单不枉我水这么一段。
前面提到,可以通过一些方式获取到游戏下载资源文件的网址。通过这个地址,我们还是在 MediaPatch 目录下,尝试下载 MediaCatalog.bytes 文件。结果是下载成功。
我们可以推测,媒体信息文件仍然保存在该目录下,但是更换了文件名以及存储方式。仅在游戏加载的时候才会去下载这个文件,加载完成后即刻删除。
解密字节文件
解决了这个问题,我们终于可以把注意力集中在「如何从 MediaCatalog.bytes 这个文件里,提取出我们所需要的信息」这个问题上了。
从文件名上不难猜出,这个文件以字节的方式储存了媒体信息,并且可能存在特殊的格式,需要我们编写代码进行读取。
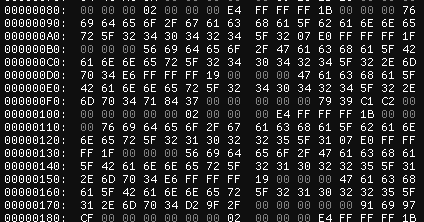
掏出我们的16进制编辑器对文件进行读取,我们能可以从转换出的 ASCII 字符中一探端倪。

可以看到,有一些零散的字符出现。我们不妨大胆猜测这些字符跟前文的 MediaCatalog.json 中的信息存在一定的对应关系。
到这里我们就不卖关子了,省略掉猜测存储信息格式的过程,直接讲述结果。
以16进制字节表示,文件格式如下:
01B9 3F 00 00E4 FF FF FF1B 00 00 0076 69 64 65 6F 2F 67 61 63 68 61 5F 62 61 6E 6E 65 72 5F 32 33 30 33 30 38 5F 3107E0 FF FF FF1F 00 00 0056 69 64 65 6F 2F 47 61 63 68 61 5F 42 61 6E 6E 65 72 5F 32 33 30 33 30 38 5F 31 2E 6D 70 34E6 FF FF FF19 00 00 0047 61 63 68 61 5F 42 61 6E 6E 65 72 5F 32 33 30 33 30 38 5F 31 2E 6D 70 344C AC 3A 00 00 00 00 0039 E5 ED B0 00 00 00 0000 0002 00 00 00
乍一看,这啥玩意,有什么规律吗?先别急,我们一一讲解。
01
这是文件开头的第一个字节,标志着文件的开始。猜测如果不发生大的修改,之后的文件都会以 01 作为开头的字节。
B9 3F 00 00
这是一个 uint32 数字,占用了4个字节,以十进制表示是 16313。这个数字代表总共有多少个媒体文件。
E4 FF FF FF 1B 00 00 00
从这里开始这是对应上文 json 文件中 video/xx 的部分,我们姑且称之为 key (对应「键值对」中的「键」)。
这是两个 uint32 数字。用心观察不难发现,如果将前面的值写为二进制,并进行按位取反操作,就可以得到后面的值。后面的数字,以十进制表示为 27。对于前面的数字,我们取反再转换为十进制,同样得到 27。这个数字代表着,后续27个字节的数据,为 key 对应的 ASCII 字符。
76 69 64 65 6F 2F 67 61 63 68 61 5F 62 61 6E 6E 65 72 5F 32 33 30 33 30 38 5F 31
我们可以数一数长度,发现恰好为 27,印证了猜想。
如前文所述,我们将这一串字节,以 ASCII 编码进行解码,得到 key 的值。感兴趣的话可以去尝试一下,看看转换结果是什么。
07
这是一个字节,对应的 ASCII 字符是 BEL。此字节仅在 key 的内容后出现,有时候可能也不会出现,目前尚未确定出现的条件。
E0 FF FF FF 1F 00 00 00
同之前的 key,此后对应 path 部分。
这是两个 uint32 数字。我们用相同的方式,得到 31,对应 path 字符数据的长度。
56 69 64 65 6F 2F 47 61 63 68 61 5F 42 61 6E 6E 65 72 5F 32 33 30 33 30 38 5F 31 2E 6D 70 34
path 的值,不多赘述。决定我们重命名后的文件名和目录。
E6 FF FF FF 19 00 00 00
同之前的 path,此后对应 FileName 部分。
这是两个 uint32 数字。我们用相同的方式,得到 25,对应 FileName 字符数据的长度。
47 61 63 68 61 5F 42 61 6E 6E 65 72 5F 32 33 30 33 30 38 5F 31 2E 6D 70 34
FileName 的值,不多赘述。
4C AC 3A 00 00 00 00 00
这是一个 uint64 数字,占用了8个字节。我们直接转换为十进制,得到 3845196。这个数字对应的是 Bytes 字段,也就是代表对应文件的大小。
39 E5 ED B0 00 00 00 00
这是一个 uint64 数字。转换为十进制,得到 2968380729。这个数字对应 Crc 字段,代表文件的 CRC 值。我们主要通过这个值来寻找需要的文件。
00 00
这是一个 uint16 数字。转换为十进制,得到 0。这个数字对应的是 IsPrologue 字段。在原来的 json 文件中,仅有少数文件具有这个字段。
02 00 00 00
这是一个 uint32 数字。转换为十进制,得到 2。这个数字对应 MediaType 字段,代表文件类型。
后续的数据,都是从 (3) 到 (16) 的重复,直到文件结束。
上述即为文件存储信息的格式。通过这个格式,我们就可以编写相应的代码,进行数据的读取和利用了。我个人是把这些信息重新转化成 json 文件,这样仍然可以利用此前的脚本进行文件的重命名,仅需要做一些微调。
结语与吐槽
写了这么多,对于文件格式应该讲解到位了。不知道此后的更新,会不会再次对文件格式进行调整。
这几天花了好多时间来研究这个新版本如何解包。如果大家有去观察国际服的资源文件,会发现他们都是直接原文件名存储,并没有进行加密转换。这不禁让人揣测,日服此次更新又是何用意。
总之,可以好好准备下接下来的总力战了。
本文作者:YoursFunny
本文链接:https://yoursfunny.top/archives/Blue-Archive-JP-Unpack-Note.html
版权声明:本文采用 CC BY-NC 4.0 进行许可。转载、引用及修改请注明出处。禁止用于商业目的。